
In the face of multiple political and market setbacks in the western world, Huawei is trying to maintain a business-as-usual stance by continuing to drive innovation with their networking products. Late last week, Huawei unveiled the latest in their CloudFabric line of data center network solutions: the CloudEngine 16800. The CloudEngine 16800 supersedes the CloudEngine 12800 as the largest capacity switch in Huawei’s networking portfolio.
The 16800 boasts a slew of new capabilities, the most prominent of which are:
- support for 48-port 400GbE line cards, and 768 400GbE ports in total per chassis which represents the highest density and scale for 400GbE ports in the data center.
- embedding of their recently announced Ascend AI chipset on switch.
- their iNetOps autonomous fault-detection capabilities.
 Other innovations, Huawei claims, include 50% lower power consumption per bit moved than competitors and improved cooling and transmission efficiency.
Other innovations, Huawei claims, include 50% lower power consumption per bit moved than competitors and improved cooling and transmission efficiency.
The CloudEngine 16800 is apparently based on Broadcom’s merchant silicon though Huawei did not provide further details. As far as AvidThink is aware, the current top-of-line Broadcom Tomahawk 3 is capable of 32 400GbE ports for 12.8 Tbps switching capacity, less than the 48 400GbE ports on a 16800 line card. We won’t speculate on how the 48 ports are achieved or any implications for latency. Huawei intimated that the 16800 will be available for early field trials in Q2 2019.
Maximum Density of 400GbE Ports to Drive Market Penetration
While the stated density of 400GbE ports in a single chassis is impressive, and although AvidThink expects that it will take other vendors some time to catch up, catch up they will. Nevertheless, that should not detract from Huawei’s engineering success in hitting this milestone first. In the worldwide switching market, IDC recently showed Cisco is in the lead — no surprise — with a 54.4% share overall, Huawei comes in second with an 8.6% share, and Arista, HPE follows closely a few percentage points behind. Huawei is likely hoping that with this round of innovation they can stay the course to increase market share, building on their 21% year-on-year growth, outpacing Cisco’s close to 4% growth, and staving off Arista’s aggressive penetration.
Embedding in-house AI Chips to Usher in the AI Era
Certainly, speed and scale are important, but potentially more significant and interesting is the embedding of the Ascend chipset onboard the switch (read our previous article on Huawei’s Ascend AI chip announcement). This chip, coupled with their packet-loss reduction algorithms, now collected under a new iLossLess umbrella term, is likely the first onboard AI system in a switch performing real-time control. This represents a step in Huawei’s desire to usher in the “AI era.”
Huawei’s iLossLess Algorithms for a Zero-Loss Data Center
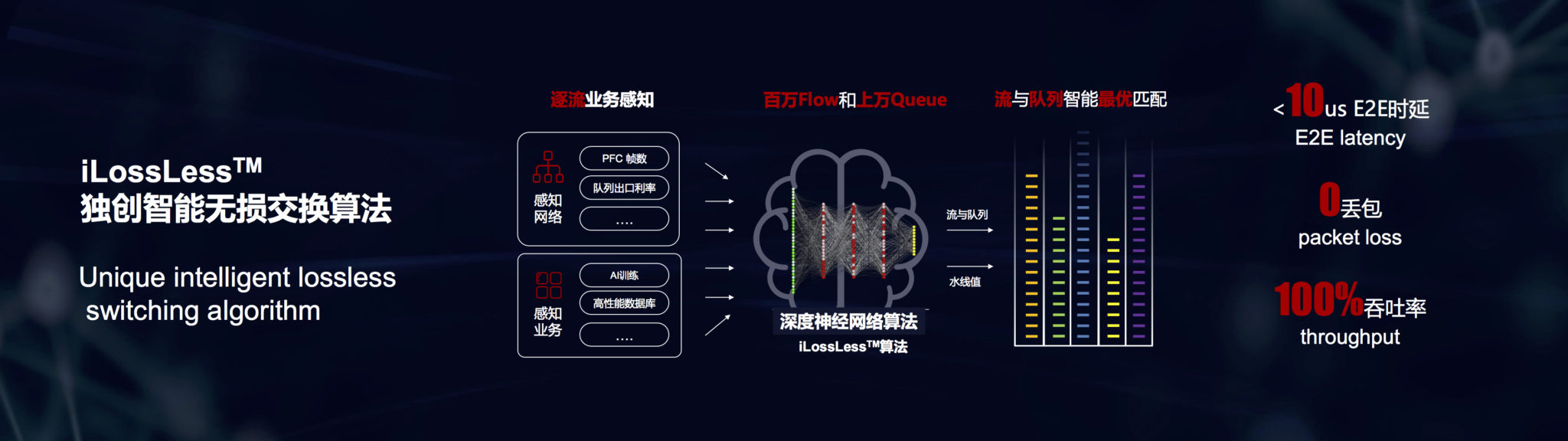 Previously, Huawei’s AI Fabric capabilities were marketed as a collection of disparate algorithms that enabled zero packet loss for HPC and storage workloads. Using converged Ethernet carrying remote direct memory access (RDMA) traffic, AI Fabric was tested by the independent European lab, EANTC. It showed improvements of 40% faster job completion times in high-performance computing (HPC) workloads and 25% improvements in IOPS for distributed storage applications compared to when AI Fabric mode was not turned on.
Previously, Huawei’s AI Fabric capabilities were marketed as a collection of disparate algorithms that enabled zero packet loss for HPC and storage workloads. Using converged Ethernet carrying remote direct memory access (RDMA) traffic, AI Fabric was tested by the independent European lab, EANTC. It showed improvements of 40% faster job completion times in high-performance computing (HPC) workloads and 25% improvements in IOPS for distributed storage applications compared to when AI Fabric mode was not turned on.
Huawei is now taking the next step by first combining these algorithms and adding more under the iLossLess moniker and then using the Ascend AI chip to help determine the right parameters to feed these algorithms. Given that the CloudEngine 16800 switch will be designed to act as the spine in a data center leaf-spine topology, Huawei’s intention is to use the AI chip to calculate parameters not just for local optimization, but to monitor, learn, and apply tuning parameters across leaf CloudEngine switches as well. Their goal is to achieve improved throughput, lower latency, and zero loss end-to-end across the entire leaf-spine fabric.
In terms of the initial training and model building, Huawei has indicated that they are using information gathered from their customers and internal testing to build initial models that will ship with the switches. These models will be updated and improved as the onboard AI chips learn and adapt to individual workloads in each data center.
Don’t miss out! Be the first to know when the 2019 Next-Gen Data Center Networking Report ships.
If you enjoyed our Next-Gen Data Center report in the past when we published under the SDxCentral brand, sign up and get notified when this year’s edition ships (end Q1 2019).
By providing your information, you will be opting in to our research report mailing list, but you have the option to opt out at anytime in our mailings.
Betting on RDMA and ROCEv2
With iLossLess and a focus on converged Ethernet, Huawei is betting that RDMA and RDMA over converged Ethernet (ROCE) will become more important, especially as data center operators eschew specialized fabrics like Infiniband for HPC and FibreChannel for storage. It’s a decent bet given that network engineers prefer simplified operations and using converged Ethernet allows them to use the same switches, cabling schemes, operations, troubleshooting, and management tools to manage HPC/storage workloads as well as regular data center application workloads.
Further, a move to AI/ML workloads favors lossless fabrics supporting RDMA. EANTC’s HPC tests, which are also applicable to big data analytics and AI/ML workloads, indicate that having a strong ROCEv2 implementation can dramatically improve job completion times. And a recent presentation by the Hong Kong University of Science & Technology at SuperComputing Asia 2018 demonstrated that using RDMA instead of regular TCP can double ML processing capability.
The other trend that supports Huawei’s bet is the move towards the NVMe interface and protocol. NVMe, due to its ability to leverage the inherent parallelism of solid-state arrays, has gained popularity within servers. NVMe over Fabrics (NVMeOF) is a method of running the NVMe protocol between servers over RDMA and a lossless fabric. While NVMeOF/RDMA supports multiple transport types including Infiniband, ROCEv2 and iWARP, we expect NFVMeOF to be mostly run over ROCEv2 for the same reasons stated above.
To ensure that the network fabric performs well under ROCEv2, Huawei has invested in improving their ability to reduce and eliminate packet loss on converged Ethernet fabric. Huawei’s iLossLess family of algorithms now includes a range of techniques:
- Multiple virtualized queues with elephant and mice flow detection which allows the switch to accurately spot congested flows, as it prevents sacrificing packets from mice flows while appropriately managing elephant flows.
- Dynamic waterlines which affects when congestion notices are triggered, maximizing use of buffers.
- Fast back pressure that allows the switch to generate congestion messages instead of waiting on the receiving server, thus preventing senders from pushing packets too quickly and overwhelming buffers.
Previously, some of these techniques were implemented on earlier CloudEngine switches through the use of an onboard FPGA. With an Ascend AI chip embedded on the switch, we expect to see further evolution of these techniques and more accurate parameter setting and tuning based on the unique workloads that each switch will experience.
AI-Assisted Automated Troubleshooting
Finally, Huawei is combining AI capabilities with their FabricInsight network analyzer to enable a distributed O&M architecture. Huawei claims that they have identified over 72 types of common faults that can be automatically identified in seconds and located in minutes, saving hours of troubleshooting time.
With this announcement, Huawei has made good on their promise in October 2018 to start embedding their AI chips everywhere and leverage their homegrown AI technology to improve their products. The CloudEngine 16800 switch performance specifications are quite impressive on their own for a high-end data switch. And we’ll be watching, as Q2 comes around, to see how the switch and Huawei’s new AI technologies perform to reduce latency, eliminate loss as well as accelerate fault detection, isolation, and mitigation in real-world data center settings.